-
Design Pattern
- Singleton Design Pattern
- Factory Design Pattern
- Factory Method Design Pattern
- Abstract Factory Design Pattern
- Builder Design Pattern
- Prototype Design Pattern
- Object Pool Design Pattern
- Chain of Responsibility Design Pattern
- Command Design Pattern
- Interpreter Design Pattern
- Iterator Design Pattern
- Mediator Design Pattern
- Memento Design Pattern
- Observer Design Pattern
- Observer Design Pattern - Xử Lý Exception
- Strategy Design Pattern
- Template Method Design Pattern
- Visitor Design Pattern
- Null Object Design Pattern
- Adapter Design Pattern
- Bridge Design Pattern
- Composite Design Pattern
- Decorator Design Pattern
- Flyweight Design Pattern
- Proxy Design Pattern
- S.O.L.I.D
- Clean code
- Lập trình socket
- Java Core
- Multi-Thread
- Spring
- Java Web
- Memory Caching
- Message Queue
- DevOps
- Xây dựng một nền tảng
- MongoDB
- MySQL timestamp
- Properties vs yaml
- Kotlin
- Lập Trình Machine Learning với PyTorch
- Mã Nguồn Mở
- Ezy HTTP
- Free Chat
- Một số kinh nghiệm với Git
- Review cho đồng nghiệp!
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Tuân thủ
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Lựa chọn người đi cùng
- Ngành công nghiệp phần mềm tại Việt Nam - Mới chỉ là bắt đầu.
- Ngành công nghiệp phần mềm tại Việt Nam - Dây chuyền sản xuất.
- Ngành công nghiệp phần mềm tại Việt Nam - Thị trường
- Ngành công nghiệp phần mềm tại Việt Nam - Công ăn việc làm
- Setup Dev Environment
- Hello World
- Create a Server Project
- Handle Client Requests
- Using ezyfox-server-csharp-client
- Using ezyfox-es6-client
- Client React.js Interaction
- Build And Deploy In Local
- Tham gia phát triển open source!
- Buôn có bạn, bán có phường
- Đam mê đi đâu rồi?
- Giữa lửa đam mê!
- Tương lai nào cho tester? Thay đổi để dẫn đầu xu thế!
- Tương lai nào cho tester? - Khi thế sự đổi thay!
- Tương lai nào cho lập trình viên? Khi không có hệ quy chiếu!
- Tương lai nào cho lập trình viên - Làm đến bao nhiêu tuổi?
- Tương lai nào cho lập trình viên? Có làm giàu được không?
- Tương lai nào cho lập trình viên? Có cân bằng cuộc sống được không?
- Tương lai nào cho lập trình viên - Nhảy việc đến khi nào?
- Tương lai nào cho lập trình viên - Con đường sự nghiệp (Career path)!
- Tương lai nào cho lập trình viên - Tổng kết lại!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn sơ cấp (Junior)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn trung cấp (Intermediate)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn lành nghề (Senior)!
- Giai đoạn lành nghề (Senior) - Giữa những hoang mang!
- Giai đoạn lành nghề (Senior) - Phân hoá trong doanh nghiệp!
- Con đường sự nghiệp cho lập trình viên - Trở thành chuyên gia (Expert)!
- Con đường sự nghiệp cho lập trình viên - Trở thành người ảnh hưởng (Influencer)!
- Các giai đoạn phát triển của lập trình viên - Tổng kết lại!
- Metaverse - Câu chuyện 10 nghìn CCU (Người tham gia đồng thời)
- Metaverse có khả thi ở Việt Nam?
- Lựa chọn nghề nghiệp - DevOps!
- Lựa chọn nghề nghiệp - Project Manager (PM)!
- Lựa chọn nghề nghiệp - Data Engineer!
- Lựa chọn nghề nghiệp - BackEnd Engineer!
- “Talk is cheap. Show me the code” ― Linus Torvalds
- Lựa chọn nghề nghiệp - Web Front-End Engineer!
- Lựa chọn nghề nghiệp - Mobile Engineer!
- Lựa chọn nghề nghiệp - Game Engineer!
- Lựa chọn nghề nghiệp - Product Owner!
- Tuổi trẻ cần đột phá!
- Tuổi trẻ cần sự đồng cảm!
- Tuổi trẻ - điều đáng sợ đầu tiên là gì?
- Tuổi trẻ - Điều đáng sợ thứ 2 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 3 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 4 là gì?
- Nếu tận dụng hết năng lực thì sẽ thế nào?
- Tuổi trẻ - Điều đáng sợ thứ 5 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 6 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 7 là gì?
- Tuổi trẻ - ham học hỏi là như thế nào?
- Đầu tư cho bản thân là gì?
- Học chủ động!
- Có nên quay lại công ty cũ?
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 1)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 2)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 3)
- Tự học
- Học tập tại doanh nghiệp
- Học tại trung tâm
- Cách đọc sách kỹ thuật hiệu quả
- Học trong một tổ chức mã nguồn mở.
- Câu chuyện lập trình viên - Công việc đầu tiên
- Câu chuyện lập trình viên - Mức lương đầu tiên
- Câu chuyện lập trình viên - 2018
- Định hướng là gì?
- Wordpress nguy hiểm thế nào?
- Danh sách 10 trung tâm đào tạo trình uy tín, chất lượng ở Hà Nội
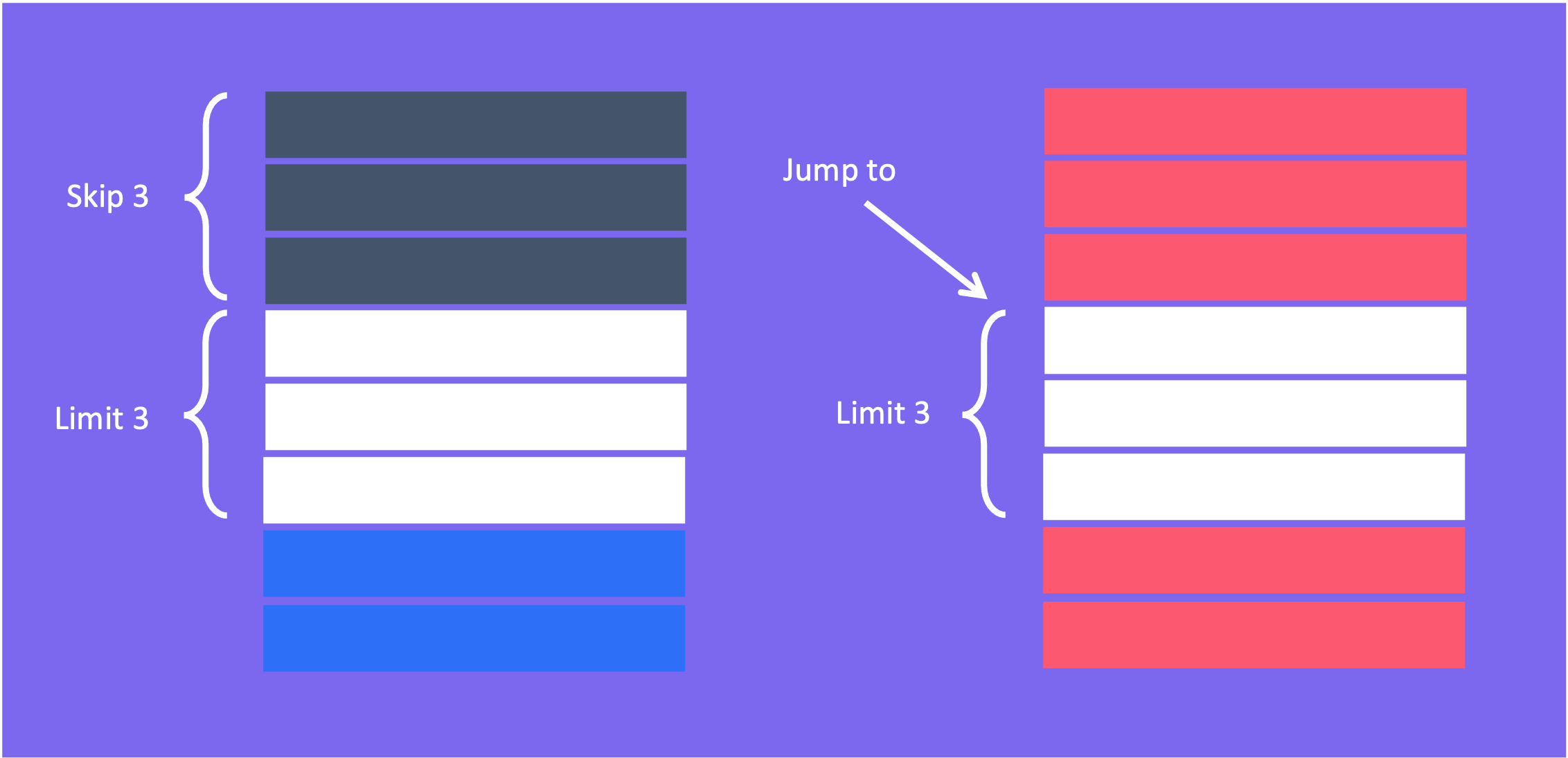
Tưởng dễ mà khó
Bài toán phân trang từ xưa đến nay chúng ta đã làm cả tỉ lần rồi, có người thì lấy hết dữ liệu ở database vài nghìn bản ghi ra rồi phân trang. Có người thì dùng skip (bỏ qua) x phần tử ở đầu rồi lấy y phần tử tiếp theo. Nhưng đó là chỉ khi dữ liệu của chúng ta còn ít, khi số lượng bản ghi lên đến hàng triệu như dự án blockchain của bọn mình, thì câu chuyện lại khác. Lúc này những thứ dễ dàng lại trở nên khó khăn, bọn mình đã test thử và đối với bảng có 1 triệu bản ghi thì những trang ở cuối có khi mất đến tận 30 giây, dẫn đến hàng loạt hệ luỵ khác. Vậy nên bọn mình phải sử dụng phân trang theo con trỏ.
Bài toán thực tế
Chúng ta hãy sử dụng dự án quản lý sách để làm ví dụ nhé, cụ thể hơn là tính năng liệt kê danh sách sách đang có. Thông tin sách bao gồm:
public class Book {
private Long id;
private Long categoryId;
private Long authorId;
private String name;
private BigDecimal price;
private LocalDate releaseDate;
private LocalDateTime releaseTime;
}Chúng ta sẽ cần sắp xếp sách theo giá theo chiều giảm dần, và nếu có 2 quyển sách cùng giá, chúng ta sẽ sắp xếp theo id theo chiều giảm dần.
Phân trang lười biếng
Đây là kiểu phân trang mà hồi đầu mới đi làm hoặc đối với các dự án dữ liệu dưới 100 nghìn bản ghi hay dùng cho nhanh. Nó chỉ đơn giản là lấy tất cả dữ liệu trong bảng trả về cho UI, còn việc phân trang thế nào thì do UI tự quyết. Code sẽ kiểu thế này:
@DoGet("/book/list")
public List<BookRawResponse> getBooks() {
final List<BookRawData> dataList = bookService.getAllBooks();
return dataToResponseConverter.toRawResponseList(dataList);
}Ưu điểm
- Nhanh gọn, đơn giản, dễ làm
- Chúng ta có thể phân trang theo nhiều kiểu: theo số trang hay theo kiểu vuốt, hay kiểu next, previous
Nhược điểm
Đối với những bảng có trên 100 nghìn bản ghi thì việc lấy và trả về dữ liệu cho client là tương đối nhọc nhằn, chưa kể nó nó sẽ block connection của database, dẫn đến trường hợp database server hết khả năng đáp ứng và báo lỗi too many connections
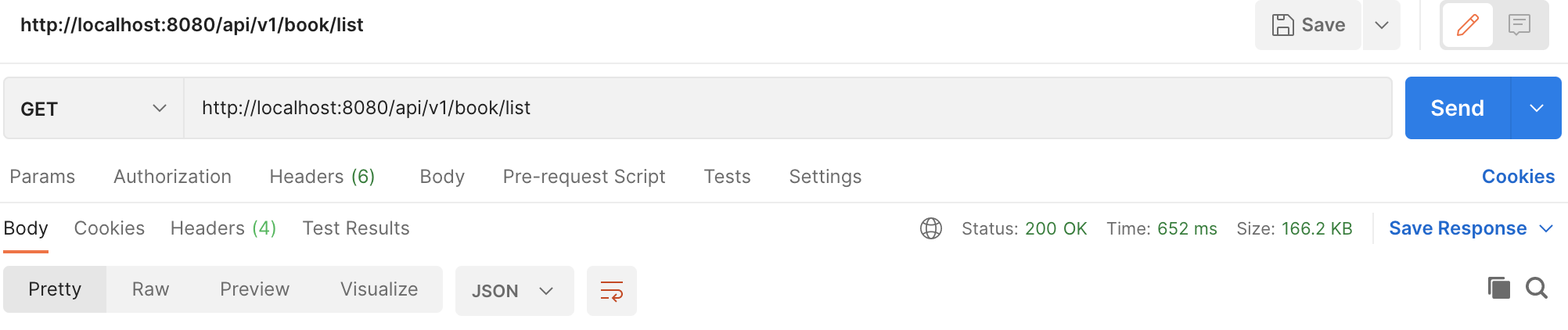
Như chúng ta có thể trên hình, với khoảng 1000 bản ghi sẽ tốn 652ms và 166.2KB, nếu 100 nghìn bản ghi thi sẽ là 16.6 MB, đây là một con số tương đối lớn
Phân trang kiểu offset
Một kiểu phân trang hơi lười biếng 1 chút hay được dùng với bảng có dưới 1 triệu bản ghi đó là dùng offset. Kiểu này sẽ giúp chúng giảm thiểu được số lượng dữ liệu cần lấy, câu lệnh SQL sẽ kiểu:
select * from book offset = n limit = m order by price desc, id descCơ chế hoạt động
Cơ sở dữ liệu sẽ duyệt qua toàn bộ các bản ghi thoả mãn điều kiện cho đến khi gặp bản ghi thứ n sẽ lấy ra m bản ghi và kết thúc câu truy vấn.
Ưu điểm
- Nhanh gọn, đơn giản, dễ làm
- Chúng ta có thể phân trang theo nhiều kiểu: theo kiểu vuốt, hay kiểu next, previous
- Muốn phân trang theo kiểu số trang, chúng ta sẽ cần gọi thực hiện 1 truy vấn count để lấy tổng số bản ghi đang có trong bản.
Nhược điểm
Đối với những bảng có trên 1 triệu bản ghi thì việc lấy những bản ghi ở cuối và trả về dữ liệu cho client sẽ bị chậm vì bất cầu lần truy vấn nào nó cũng phải đi qua tất cả các bản ghi hợp lệ.
Như chúng ta có thể trên hình, với khoảng 16000 bản ghi sẽ tốn 32ms và 1.71KB 
Phân trang kiểu con trỏ (cursor)
Đối với những bảng có trên 1 triệu bản ghi, lựa chọn tốt nhất sẽ là sử dụng con trỏ.
Cơ chế hoạt động
Tận dụng cơ chế đánh index mà bản chất là BTree của các hệ quản trị cơ sở dữ liệu, chúng ta sẽ chỉ định vị trí mà chúng ta sẽ chuyển con trỏ đến, hãy xem câu lệnh SQL để mình giải thích rõ hơn nhé:
select * from book e
where e.price > ?0 or (e.price = ?0 and e.id > ?1)
order by e.price desc, e.id desc
limit 100Bỏi vì chúng ta đã đánh index cho trường price và id rồi nên tốc độ tìm kiếm sẽ là sẽ là O(nlog(n)) nghĩa là dù có 1 tỉ bản ghi thì cũng sẽ mất O(9log(10)) ~ 30 lần tìm kiếm, nó sẽ chỉ cần 1 vài bước nhảy là đến được vị trí bản ghi bắt đầu trang mà chúng ta muốn lấy mà không phải lặp qua tất cả các bản ghi hợp lệ nữa, chính vì vậy mà nó rất nhanh
Ưu điểm
- Tốc độ rất nhanh, bạn có thể thấy với 16 nghìn bản ghi thì nó cũng chỉ mất 9ms để lấy ra được các bản ghi ở cuối
- Phù hợp với 2 kiểu phân trang: vuốt và next, previous

Nhược điểm
- Hơi khó hiểu và khó cài đặt
- Bạn phải tạo nhiều API để lấy được trang đầu, trang cuối, trang trước, trang sau
- Không phù hợp với kiểu phân trang theo kiểu số trang
Source code đầy đủ bạn có thể tham khảo tại đây nhé.
Những lưu ý
- Để làm phân trang theo kiểu offset hoặc con trỏ thì điều kiện bắt buộc là chúng ta phải đánh index, nếu không đánh index, tốc độ sẽ không được cải thiện
- Nếu bảng của bạn chưa được đánh index nhưng dữ liệu đang có trên 1 triệu bản ghi, hãy cân nhắc đến việc đồng bộ dữ liệu sang một bảng khác đã cài đặt sẵn index, và sử dụng bảng này để lấy dữ liệu phân trang.
- Câu lệnh
countrất chậm nên bạn không nên phân trang theo kiểu số trang, hãy phân trang theo kiểu vuốt hoặc next, previous
Tổng kết
Với sự gia tăng không ngừng của dữ liệu thì bài toán phân trang cũng sẽ phức tạp theo. Không phải ngẫu nhiên mà tính năng phân trang theo số đã biến mất hoàn toàn khỏi các giao diện của google, thay vào đó là kiểu vuốt, next và previous, đó chính là những ứng dụng của phân trang kiểu con trỏ.
Tuy nhiên với những bài toán đơn giản và dữ liệu ít thì việc lấy toàn bộ dữ liệu về rồi phân trang, hay lấy dữ liệu theo offset cũng không phải quá tồi tệ, hãy áp dụng mềm dẻo để phù hợp với dự án của mình các bạn nhé
Tham khảo
-
Design Pattern
- Singleton Design Pattern
- Factory Design Pattern
- Factory Method Design Pattern
- Abstract Factory Design Pattern
- Builder Design Pattern
- Prototype Design Pattern
- Object Pool Design Pattern
- Chain of Responsibility Design Pattern
- Command Design Pattern
- Interpreter Design Pattern
- Iterator Design Pattern
- Mediator Design Pattern
- Memento Design Pattern
- Observer Design Pattern
- Observer Design Pattern - Xử Lý Exception
- Strategy Design Pattern
- Template Method Design Pattern
- Visitor Design Pattern
- Null Object Design Pattern
- Adapter Design Pattern
- Bridge Design Pattern
- Composite Design Pattern
- Decorator Design Pattern
- Flyweight Design Pattern
- Proxy Design Pattern
- S.O.L.I.D
- Clean code
- Lập trình socket
- Java Core
- Multi-Thread
- Spring
- Java Web
- Memory Caching
- Message Queue
- DevOps
- Xây dựng một nền tảng
- MongoDB
- MySQL timestamp
- Properties vs yaml
- Kotlin
- Lập Trình Machine Learning với PyTorch
- Mã Nguồn Mở
- Ezy HTTP
- Free Chat
- Một số kinh nghiệm với Git
- Review cho đồng nghiệp!
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Tuân thủ
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Lựa chọn người đi cùng
- Ngành công nghiệp phần mềm tại Việt Nam - Mới chỉ là bắt đầu.
- Ngành công nghiệp phần mềm tại Việt Nam - Dây chuyền sản xuất.
- Ngành công nghiệp phần mềm tại Việt Nam - Thị trường
- Ngành công nghiệp phần mềm tại Việt Nam - Công ăn việc làm
- Setup Dev Environment
- Hello World
- Create a Server Project
- Handle Client Requests
- Using ezyfox-server-csharp-client
- Using ezyfox-es6-client
- Client React.js Interaction
- Build And Deploy In Local
- Tham gia phát triển open source!
- Buôn có bạn, bán có phường
- Đam mê đi đâu rồi?
- Giữa lửa đam mê!
- Tương lai nào cho tester? Thay đổi để dẫn đầu xu thế!
- Tương lai nào cho tester? - Khi thế sự đổi thay!
- Tương lai nào cho lập trình viên? Khi không có hệ quy chiếu!
- Tương lai nào cho lập trình viên - Làm đến bao nhiêu tuổi?
- Tương lai nào cho lập trình viên? Có làm giàu được không?
- Tương lai nào cho lập trình viên? Có cân bằng cuộc sống được không?
- Tương lai nào cho lập trình viên - Nhảy việc đến khi nào?
- Tương lai nào cho lập trình viên - Con đường sự nghiệp (Career path)!
- Tương lai nào cho lập trình viên - Tổng kết lại!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn sơ cấp (Junior)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn trung cấp (Intermediate)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn lành nghề (Senior)!
- Giai đoạn lành nghề (Senior) - Giữa những hoang mang!
- Giai đoạn lành nghề (Senior) - Phân hoá trong doanh nghiệp!
- Con đường sự nghiệp cho lập trình viên - Trở thành chuyên gia (Expert)!
- Con đường sự nghiệp cho lập trình viên - Trở thành người ảnh hưởng (Influencer)!
- Các giai đoạn phát triển của lập trình viên - Tổng kết lại!
- Metaverse - Câu chuyện 10 nghìn CCU (Người tham gia đồng thời)
- Metaverse có khả thi ở Việt Nam?
- Lựa chọn nghề nghiệp - DevOps!
- Lựa chọn nghề nghiệp - Project Manager (PM)!
- Lựa chọn nghề nghiệp - Data Engineer!
- Lựa chọn nghề nghiệp - BackEnd Engineer!
- “Talk is cheap. Show me the code” ― Linus Torvalds
- Lựa chọn nghề nghiệp - Web Front-End Engineer!
- Lựa chọn nghề nghiệp - Mobile Engineer!
- Lựa chọn nghề nghiệp - Game Engineer!
- Lựa chọn nghề nghiệp - Product Owner!
- Tuổi trẻ cần đột phá!
- Tuổi trẻ cần sự đồng cảm!
- Tuổi trẻ - điều đáng sợ đầu tiên là gì?
- Tuổi trẻ - Điều đáng sợ thứ 2 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 3 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 4 là gì?
- Nếu tận dụng hết năng lực thì sẽ thế nào?
- Tuổi trẻ - Điều đáng sợ thứ 5 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 6 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 7 là gì?
- Tuổi trẻ - ham học hỏi là như thế nào?
- Đầu tư cho bản thân là gì?
- Học chủ động!
- Có nên quay lại công ty cũ?
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 1)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 2)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 3)
- Tự học
- Học tập tại doanh nghiệp
- Học tại trung tâm
- Cách đọc sách kỹ thuật hiệu quả
- Học trong một tổ chức mã nguồn mở.
- Câu chuyện lập trình viên - Công việc đầu tiên
- Câu chuyện lập trình viên - Mức lương đầu tiên
- Câu chuyện lập trình viên - 2018
- Định hướng là gì?
- Wordpress nguy hiểm thế nào?
- Danh sách 10 trung tâm đào tạo trình uy tín, chất lượng ở Hà Nội