-
Design Pattern
- Singleton Design Pattern
- Factory Design Pattern
- Factory Method Design Pattern
- Abstract Factory Design Pattern
- Builder Design Pattern
- Prototype Design Pattern
- Object Pool Design Pattern
- Chain of Responsibility Design Pattern
- Command Design Pattern
- Interpreter Design Pattern
- Iterator Design Pattern
- Mediator Design Pattern
- Memento Design Pattern
- Observer Design Pattern
- Observer Design Pattern - Xử Lý Exception
- Strategy Design Pattern
- Template Method Design Pattern
- Visitor Design Pattern
- Null Object Design Pattern
- Adapter Design Pattern
- Bridge Design Pattern
- Composite Design Pattern
- Decorator Design Pattern
- Flyweight Design Pattern
- Proxy Design Pattern
- S.O.L.I.D
- Clean code
- Lập trình socket
- Java Core
- Multi-Thread
- Spring
- Java Web
- Memory Caching
- Message Queue
- DevOps
- Xây dựng một nền tảng
- MongoDB
- MySQL timestamp
- Properties vs yaml
- Kotlin
- Lập Trình Machine Learning với PyTorch
- Mã Nguồn Mở
- Ezy HTTP
- Free Chat
- Một số kinh nghiệm với Git
- Review cho đồng nghiệp!
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Tuân thủ
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Lựa chọn người đi cùng
- Ngành công nghiệp phần mềm tại Việt Nam - Mới chỉ là bắt đầu.
- Ngành công nghiệp phần mềm tại Việt Nam - Dây chuyền sản xuất.
- Ngành công nghiệp phần mềm tại Việt Nam - Thị trường
- Ngành công nghiệp phần mềm tại Việt Nam - Công ăn việc làm
- Setup Dev Environment
- Hello World
- Create a Server Project
- Handle Client Requests
- Using ezyfox-server-csharp-client
- Using ezyfox-es6-client
- Client React.js Interaction
- Build And Deploy In Local
- Tham gia phát triển open source!
- Buôn có bạn, bán có phường
- Đam mê đi đâu rồi?
- Giữa lửa đam mê!
- Tương lai nào cho tester? Thay đổi để dẫn đầu xu thế!
- Tương lai nào cho tester? - Khi thế sự đổi thay!
- Tương lai nào cho lập trình viên? Khi không có hệ quy chiếu!
- Tương lai nào cho lập trình viên - Làm đến bao nhiêu tuổi?
- Tương lai nào cho lập trình viên? Có làm giàu được không?
- Tương lai nào cho lập trình viên? Có cân bằng cuộc sống được không?
- Tương lai nào cho lập trình viên - Nhảy việc đến khi nào?
- Tương lai nào cho lập trình viên - Con đường sự nghiệp (Career path)!
- Tương lai nào cho lập trình viên - Tổng kết lại!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn sơ cấp (Junior)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn trung cấp (Intermediate)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn lành nghề (Senior)!
- Giai đoạn lành nghề (Senior) - Giữa những hoang mang!
- Giai đoạn lành nghề (Senior) - Phân hoá trong doanh nghiệp!
- Con đường sự nghiệp cho lập trình viên - Trở thành chuyên gia (Expert)!
- Con đường sự nghiệp cho lập trình viên - Trở thành người ảnh hưởng (Influencer)!
- Các giai đoạn phát triển của lập trình viên - Tổng kết lại!
- Metaverse - Câu chuyện 10 nghìn CCU (Người tham gia đồng thời)
- Metaverse có khả thi ở Việt Nam?
- Lựa chọn nghề nghiệp - DevOps!
- Lựa chọn nghề nghiệp - Project Manager (PM)!
- Lựa chọn nghề nghiệp - Data Engineer!
- Lựa chọn nghề nghiệp - BackEnd Engineer!
- “Talk is cheap. Show me the code” ― Linus Torvalds
- Lựa chọn nghề nghiệp - Web Front-End Engineer!
- Lựa chọn nghề nghiệp - Mobile Engineer!
- Lựa chọn nghề nghiệp - Game Engineer!
- Lựa chọn nghề nghiệp - Product Owner!
- Tuổi trẻ cần đột phá!
- Tuổi trẻ cần sự đồng cảm!
- Tuổi trẻ - điều đáng sợ đầu tiên là gì?
- Tuổi trẻ - Điều đáng sợ thứ 2 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 3 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 4 là gì?
- Nếu tận dụng hết năng lực thì sẽ thế nào?
- Tuổi trẻ - Điều đáng sợ thứ 5 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 6 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 7 là gì?
- Tuổi trẻ - ham học hỏi là như thế nào?
- Đầu tư cho bản thân là gì?
- Học chủ động!
- Có nên quay lại công ty cũ?
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 1)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 2)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 3)
- Tự học
- Học tập tại doanh nghiệp
- Học tại trung tâm
- Cách đọc sách kỹ thuật hiệu quả
- Học trong một tổ chức mã nguồn mở.
- Câu chuyện lập trình viên - Công việc đầu tiên
- Câu chuyện lập trình viên - Mức lương đầu tiên
- Câu chuyện lập trình viên - 2018
- Định hướng là gì?
- Wordpress nguy hiểm thế nào?
- Danh sách 10 trung tâm đào tạo trình uy tín, chất lượng ở Hà Nội
Một tư duy khác
Nếu như ưu điểm của các message queue như RabbitMQ hay ActiveMQ nằm ở khả năng điều phối, quản lý và đảm bảo thứ tự cho các message thì nó cũng phải đánh đổi lại bằng dung lượng bộ nhớ và một ít hiệu năng, vậy bây giờ đối với những bài toán mà không cần quan tâm điếm thứ tự của message, các bài toán đòi hỏi khả năng gửi nhận dữ liệu cực lớn như bài toán lưu log thì sao? Rõ ràng là RabbitMQ hay ActiveMQ sẽ không thể đáp ứng được, đó là khi Kafka ra đời.
Giới thiệu
Kafka là một trong những framework do LinkedIn phát triển do nhu cầu kết nối hệ thống của họ. Do tính chất là một công ty cung cấp mạng xã hội việc làm lớn nhất thế giới hiện nay, hàng ngày có đến hàng trăm triệu, hàng tỉ lượt truy cập thì khối lượng dữ liệu trao đổi trong hệ thống là cực kì lớn, tuy nhiên phần lớn những dữ liệu của người dùng đều là những dữ liệu dạng log, tức là những dữ liệu không đòi hỏi phải cập nhật theo thứ tự hay phải quản lý phiên bản (tính chât ACID), nên Kafka rất phù hợp. Hiện tại thì Kafka đang được tiếp tục duy trì và phát triển bởi tổ chức Apache.
Kafka có gì?
Hết phần giới thiệu hơi nhàm chán thì bây giờ đến phần thú vị nhất và được mọi người quan tâm nhất đây. Vậy kafka có gì mà hay ho vậy? Kafka khác biệt với các MQ 4 điểm chính sau:
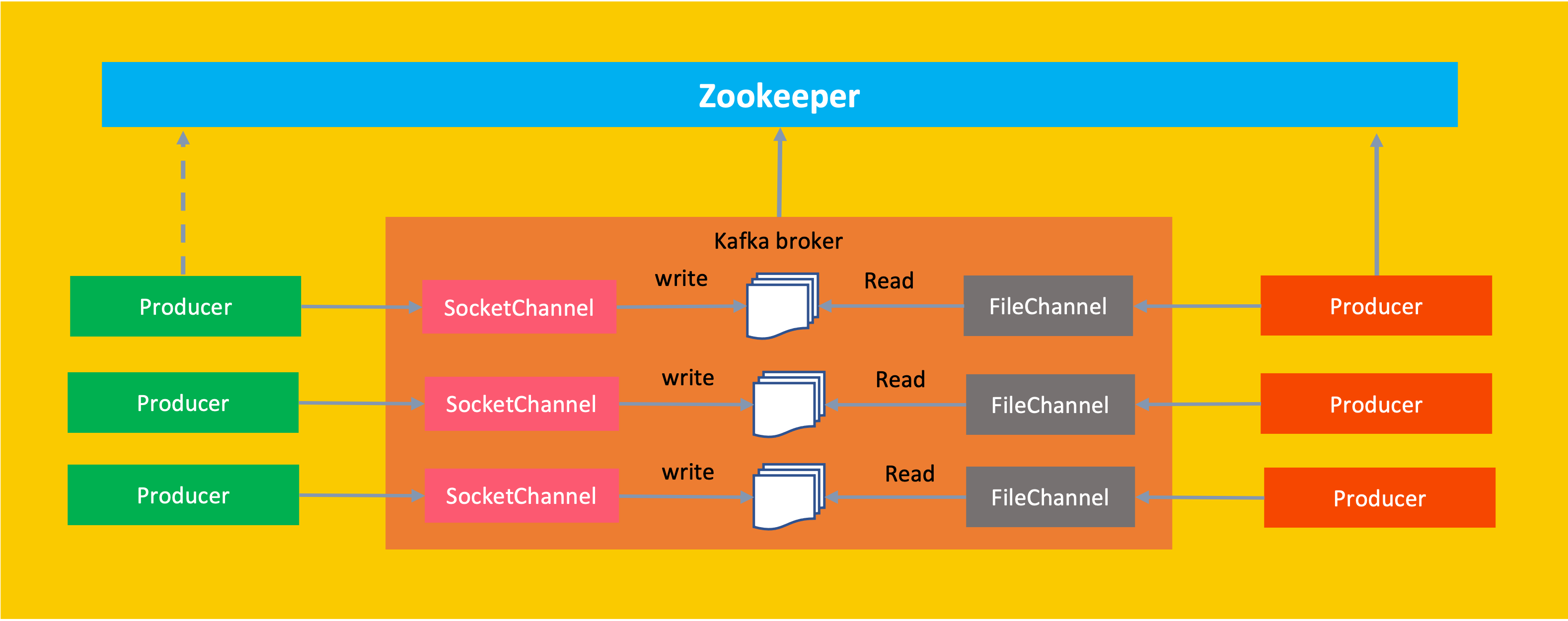
- Kafka broker không lưu message ở bộ nhớ (RAM) mà lưu xuống file, đây là điểm nhấn rất mạnh của kafka, nó đảm bảo rằng chỉ với một vài GB RAM bạn cũng có thể lưu bao nhiêu message cũng được với dung lượng ổ đĩa có thể lên đến hàng TB, điều này giúp cho mọi dữ liệu từ rất nhiều nguồn (producer) có thể gửi đến Broker mà không bị từ chối
- Broker không ngay lập tức gửi dữ liệu đến consumer mà do consumer chủ động gọi đến Broker để lấy dữ liệu, điều này giúp cho dữ liệu được ghi bền ở broker mà không sợ bị mất đi ngay cả khi broker bị die
- Consumer không lấy từng message mà lấy hết tất cả dữ liệu được lưu trong file ở dạng byte[], điều này giúp cho Kafka broker không phải tốn CPU để deserialize và serialize dữ liệu, chúng ta gọi nó là cơ chế Zero Copy Zero ở đây nghĩa là không mất nhiều chi phí cho CPU
- Kafka thường đi cùng với Zookeeper, chúng ta có thể sử dụng luôn Zookeeper để làm HA cho hệ thống mà không cần dùng thêm bất cứ dịch vụ nào
Nhược điểm
Mọi thứ đều có 2 mặt của vấn đề và Kafka cũng vậy, nó cũng có một số nhược điểm:
- Nói gì thì nói việc đọc ghi dữ liệu từ file không thể nào nhanh bằng truy cập trên bộ nhớ (RAM) được, nên nếu sử dụng những nghiệp vụ giống với MQ sẽ có thể cho kết quả chậm hơn
- Việc đảm bảo thứ tự của message là tương đối khó khăn và thực lòng mình nghĩ không nên làm như vậy
Kafka phù hợp với?
Theo kinh nghiệm sử dụng của mình thì kafka phù hợp với:
- Các hệ thống log mà hiện nay tiêu biểu nhất là hệ thống ELK
- Các hệ thống không đòi hỏi tốc độ quá cao, ví dụ các hệ thống báo cáo hoặc đồng bộ dữ liệu
- Mình cũng đã từng thấy một công ty sử dụng cho hệ thống chat realtime của họ
Một sự hiểu nhầm
Chắc hẳn nhiều bạn ở đây đã đọc nhiều tài liệu hay blog và họ hay dùng từ stream dữ liệu đúng không? Và rất nhiều bạn nhầm nó với hệ thống livestreaming video, nhưng rất tiếc là không phải vậy, stream ở đây ý là việc gửi nhận dữ liệu ở dạng byte array mà không phải serialize hay deserialize gì hết, còn các hệ thống media live streaming thường dùng UDP thì mới đảm bảo được tốc độ khung hình trên giây được.
Tổng kết
Nhìn chung kafa phù hợp cho rất nhiều bàn toán hơn so với các MQ khác, nên hiện nay rất nhiều công ty hay tập đoàn sử dụng Kafka là chủ yếu, còn các nghiệp vụ cần gọi RPC ghì có thể dùng gRPC cũng là một lựa chọn hợp lý, tuy nhiên ngoài các hệ thống thu thập log ra thì MQ theo mình vẫn là phù hợp
Tham khảo
-
Design Pattern
- Singleton Design Pattern
- Factory Design Pattern
- Factory Method Design Pattern
- Abstract Factory Design Pattern
- Builder Design Pattern
- Prototype Design Pattern
- Object Pool Design Pattern
- Chain of Responsibility Design Pattern
- Command Design Pattern
- Interpreter Design Pattern
- Iterator Design Pattern
- Mediator Design Pattern
- Memento Design Pattern
- Observer Design Pattern
- Observer Design Pattern - Xử Lý Exception
- Strategy Design Pattern
- Template Method Design Pattern
- Visitor Design Pattern
- Null Object Design Pattern
- Adapter Design Pattern
- Bridge Design Pattern
- Composite Design Pattern
- Decorator Design Pattern
- Flyweight Design Pattern
- Proxy Design Pattern
- S.O.L.I.D
- Clean code
- Lập trình socket
- Java Core
- Multi-Thread
- Spring
- Java Web
- Memory Caching
- Message Queue
- DevOps
- Xây dựng một nền tảng
- MongoDB
- MySQL timestamp
- Properties vs yaml
- Kotlin
- Lập Trình Machine Learning với PyTorch
- Mã Nguồn Mở
- Ezy HTTP
- Free Chat
- Một số kinh nghiệm với Git
- Review cho đồng nghiệp!
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Tuân thủ
- Kinh nghiệm phát triển dự án phức tạp, nhiều người - Lựa chọn người đi cùng
- Ngành công nghiệp phần mềm tại Việt Nam - Mới chỉ là bắt đầu.
- Ngành công nghiệp phần mềm tại Việt Nam - Dây chuyền sản xuất.
- Ngành công nghiệp phần mềm tại Việt Nam - Thị trường
- Ngành công nghiệp phần mềm tại Việt Nam - Công ăn việc làm
- Setup Dev Environment
- Hello World
- Create a Server Project
- Handle Client Requests
- Using ezyfox-server-csharp-client
- Using ezyfox-es6-client
- Client React.js Interaction
- Build And Deploy In Local
- Tham gia phát triển open source!
- Buôn có bạn, bán có phường
- Đam mê đi đâu rồi?
- Giữa lửa đam mê!
- Tương lai nào cho tester? Thay đổi để dẫn đầu xu thế!
- Tương lai nào cho tester? - Khi thế sự đổi thay!
- Tương lai nào cho lập trình viên? Khi không có hệ quy chiếu!
- Tương lai nào cho lập trình viên - Làm đến bao nhiêu tuổi?
- Tương lai nào cho lập trình viên? Có làm giàu được không?
- Tương lai nào cho lập trình viên? Có cân bằng cuộc sống được không?
- Tương lai nào cho lập trình viên - Nhảy việc đến khi nào?
- Tương lai nào cho lập trình viên - Con đường sự nghiệp (Career path)!
- Tương lai nào cho lập trình viên - Tổng kết lại!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn sơ cấp (Junior)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn trung cấp (Intermediate)!
- Con đường sự nghiệp cho lập trình viên - Giai đoạn lành nghề (Senior)!
- Giai đoạn lành nghề (Senior) - Giữa những hoang mang!
- Giai đoạn lành nghề (Senior) - Phân hoá trong doanh nghiệp!
- Con đường sự nghiệp cho lập trình viên - Trở thành chuyên gia (Expert)!
- Con đường sự nghiệp cho lập trình viên - Trở thành người ảnh hưởng (Influencer)!
- Các giai đoạn phát triển của lập trình viên - Tổng kết lại!
- Metaverse - Câu chuyện 10 nghìn CCU (Người tham gia đồng thời)
- Metaverse có khả thi ở Việt Nam?
- Lựa chọn nghề nghiệp - DevOps!
- Lựa chọn nghề nghiệp - Project Manager (PM)!
- Lựa chọn nghề nghiệp - Data Engineer!
- Lựa chọn nghề nghiệp - BackEnd Engineer!
- “Talk is cheap. Show me the code” ― Linus Torvalds
- Lựa chọn nghề nghiệp - Web Front-End Engineer!
- Lựa chọn nghề nghiệp - Mobile Engineer!
- Lựa chọn nghề nghiệp - Game Engineer!
- Lựa chọn nghề nghiệp - Product Owner!
- Tuổi trẻ cần đột phá!
- Tuổi trẻ cần sự đồng cảm!
- Tuổi trẻ - điều đáng sợ đầu tiên là gì?
- Tuổi trẻ - Điều đáng sợ thứ 2 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 3 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 4 là gì?
- Nếu tận dụng hết năng lực thì sẽ thế nào?
- Tuổi trẻ - Điều đáng sợ thứ 5 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 6 là gì?
- Tuổi trẻ - Điều đáng sợ thứ 7 là gì?
- Tuổi trẻ - ham học hỏi là như thế nào?
- Đầu tư cho bản thân là gì?
- Học chủ động!
- Có nên quay lại công ty cũ?
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 1)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 2)
- Làm cho startup (công ty nhỏ) hay làm cho công ty lớn? (Phần 3)
- Tự học
- Học tập tại doanh nghiệp
- Học tại trung tâm
- Cách đọc sách kỹ thuật hiệu quả
- Học trong một tổ chức mã nguồn mở.
- Câu chuyện lập trình viên - Công việc đầu tiên
- Câu chuyện lập trình viên - Mức lương đầu tiên
- Câu chuyện lập trình viên - 2018
- Định hướng là gì?
- Wordpress nguy hiểm thế nào?
- Danh sách 10 trung tâm đào tạo trình uy tín, chất lượng ở Hà Nội